Hello friends this is a follow-up to my earlier post related to gRPC Vs Restconf and as promised below is a quick summary on Protobuf (the idea that made gRPC look so good).

Before I summarize Protobuf, let's revisit what serialization is? Serialization is taking a complex data structure and serializing it into a string that can be sent over a connection. The recipient will use the de-serialization process to recover the original data structure. Serialization is also required when you want to save data structure to a file. Some popular forms of serialization are JSON, YAML, XML, and protocol buffers(Protobuf).
Protobuf is a method of serializing data that can be transmitted over wire or be stored in a file.
Two keywords to remember when we talk about Protobuf - Protobuf is platform-neutral and highly optimized for microservices architecture.
As of 2019, Google has over 48000 Protobuf message types in 12000 .proto files.
Speed:
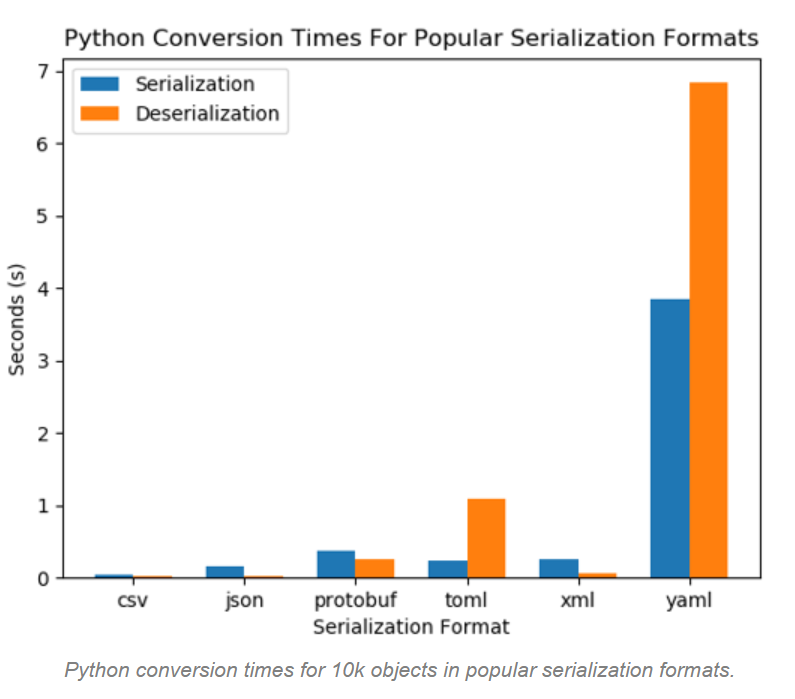
Protobuf is faster than XML/JSON serialization as it offloads the description of data in a proto file.
20-100x times faster than XML
Network bandwidth:
Protobuf utilizes binary transmission format over string used by JSON/XML thus less bandwidth is required during transmission.
3-10X smaller than JSON/XML
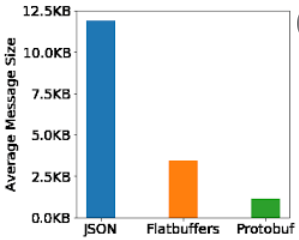
Throughput:
Protobuf payload size is ~60% smaller than JSON.
JSON is self-contained while Protobuf utilizes schema(.proto) files to keep a record of data types and schema.
Backward compatibility:
Super easy, if the new change does not work move to your last known good proto file schema.
Polyglot support:
Protobuf support many popular programming languages like C#, Go, python, Java, Javascript.
Engineer productivity :
Protobuf support automatic client code generation using code generators, just specify the proto file with the target language.
However, there are times when JSON is a better fit:
1) Data to be human readable(protobuf is binary)
2) Data is consumed directly by a web browser(right now there is no support in web-browser for protobuf)
3) When your server-side application is in javascript.
4) JSON is self-contained (protobuf needs a proto file)
Next post gRPC :)
References:
Serialization formats - Geoffrey Hunter
My earlier post on gRPC Vs Restconf